![]()
In machine learning tasks, people often relate model development as the core process or the coolest part to show case the skillset on machine learning know-how. It is no doubts that modelling is an important core concept and deserves the attention to ensure the best model performance and robustness. However, instead of model-driven approach to enhance prediction performance, data-driven approach could also improve the prediction outputs with the associated trained model becomes more sustainable as potential changes in incoming data have been factored in during the development stage.
Why Rarity?
At the junction of post model training and pre fine-tuning, we often need to conduct analysis to understand the miss predictions in order to minimize the gap of expected values versus the prediction outputs. The gap analysis generally involves examination on the metrics and deep dive into the errors to decide the next adjustment and fine-tuning strategy. The exploration process normally involve visualization of various degrees and could be overwhelming with numerous types of similar packages with different API calls before such gap analysis could be done quickly. The tap-outs of the right visualization with the most relevant packages coupled with flexible parameters could often be a time-consuming task, as engineers need to decide which package to use, identify the exact API calls or refer to pages of documentation just to get desired plots to represent the errors of interest. This could be an iterative process depending on the granularity of the error analysis.
At the model development stage, users can proceed straight to fine-tuning with Grid-Search and hoping to improve the models without much efforts to check-out the data errors. Though this process sometimes can work, but the model could also soon be subjected to further re-training as the incoming data has changed / shifted after deployment. Therefore, error analysis on the data itself besides relying on hyperparameters during model development is a complementary process but yet crucial if we want to have more stable models that have been trained with preliminary insights on the possibility of what degree of incoming data controls shall be in-placed.
Rarity is developed to resolve such need to have a quick comprehensive error analysis on miss-predictions so engineers can have an overview on the errors and factor in some potential controls on the incoming data or include addition processing scripts to cater the potential changes to ensure the developed models are more sustainable with reduced cycles of retraining. In addition to that, early flags on anomalies and collection of outliers prepared earlier as the precautionary actions resulting from the overall error analysis could provide useful information for the next cycle of model retraining, reducing the overall development efforts.
Rarity @ A Glance
Rarity is a diagnostic library for tabular data with minimal setup to enable deep dive into datasets identifying features data that could have potentially influenced the model prediction performance. It is meant to be used at post model training phase to ease the understanding on miss predictions and carry out systematic analysis to identify the gap between actual values versus prediction values. The auto-generated gap analysis is presented as a Dash web application with flexible parameters at several feature components. The inputs needed to auto-generate gap analysis report with Rarity are solely depending on features data, yTrue and yPred values. Rarity is therefore a model agnostic package and can be used to inspect miss predictions on tabular data generated by any model frameworks through data-driven approach. The package currently supports Regression and Classification tasks. It is developed to inspect miss predictions in details down to the granularity at each data index level. The package is best viewed for Bimodal miss prediction gap analysis for side-by-side comparison benefiting most during the post model training and final phase of model fine-tuning stage. There are five core feature components covered in the auto-generated gap analysis report by Rarity:
- General Metrics
- covers general metrics used to evaluate model performance.
- Miss Predictions
- presents miss predictions scatter plot by index number
- Loss Clusters
- covers clustering info on offset values (regression) and logloss values (classification)
- xFeature Distribution
- distribution plots ranked by kl-divergence score
- Similarities
- tabulated info listing top-n data points based on similarities in features with reference to data index specified by user
Counter-Factuals is also included under Similarities component tab for classification task to better compare data points with most similar features but show different prediction outcomes. For further details on how the feature components are displayed in the web application, please checkout the examples specified in the package documentation under section Features Introduction.
Development Concept
The package was developed with minimum setup requirement and simplified package API concept in mind for fast generation of overall gap-analysis. This is to allow users to have a good overview of the model performance with core error analysis scopes covered all under a simplified package. Based on the data presented in Rarity, users can quickly conclude the extra attention needed on particular data trend/error clusters and take necessary precaution to create more comprehensive processing scripts before concluding the model state.
The package API calls that are exposed to user directly are the data_loader and GapAnalyzer. Depending on the input format of incoming data, user can choose between CSVDataLoader or DataframeLoader under data_loader module to load the dataset with Rarity. The next fields that user needs to define are the followings:
- paths of the dataset (
features,yTrue,yPred) - a specific port to spin up the analysis ( if user would like to change the default port originally set at 8000 )
- analysis type ( if the task is related to
Regression,Binary ClassificationorMulticlass Classification) - analysis title ( any cool title that users would like to name their analysis )
After defining the basic input fields, user can parse these info to GapAnalyzer. Using a simple call with .run() on the analyzer, a web-based gap analysis covering the 5 main features presented as individual component tab will be generated. Code snippets for the execution process mentioned above are shown below:
from rarity import GapAnalyzer
from rarity.data_loader import CSVDataLoader
# define the file paths
xFeatures_file = 'example_xFeatures.csv'
yTrue_file = 'example_yTrue.csv'
yPred_file_list = ['example_yPreds_model_xx.csv', 'example_yPreds_rf.csv']
model_names_list = ['model_xx', 'model_yy']
# specify which port to use, if not provided, default port is set to 8000
preferred_port = 8866
# collate all files using dataloader to transform them into the input format
# that can be processed by various internal function calls
# example : '<analysis_type>' => 'Regression'
# example : '<analysis_title>' => 'Customer Churn Prediction'
data_loader = CSVDataLoader(xFeatures_file, yTrue_file, yPred_file_list,
model_names_list, '<analysis_type>')
analyzer = GapAnalyzer(data_loader, '<analysis_title>', preferred_port)
analyzer.run()
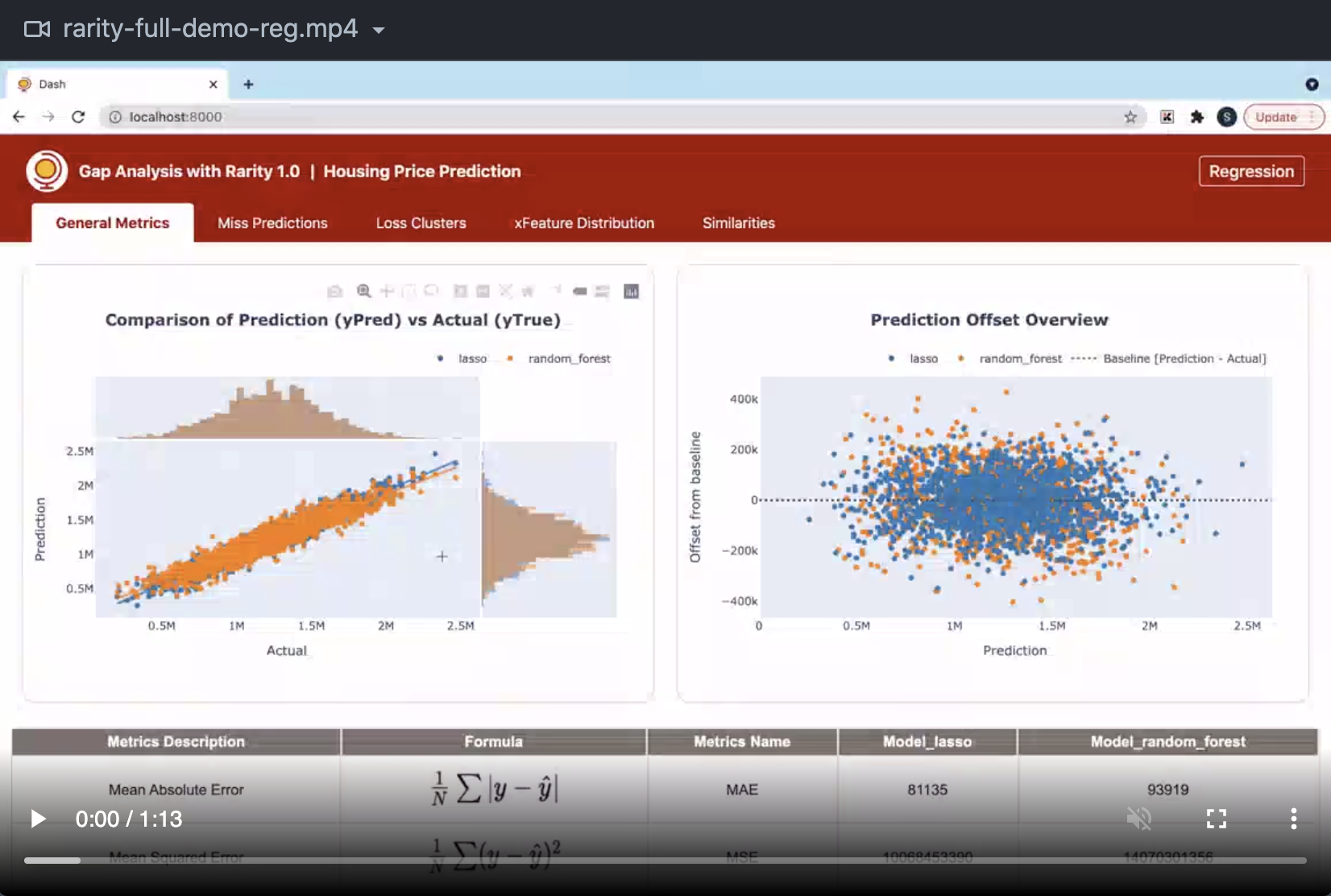
For interest to know how the various integrated sub-components work under the hood, users are welcome to check out the core components section in the package documentation.
Official Release Channel


