![]()
Every year, there are thousands of graduates from different institutions coming fresh into the job market, looking for the jobs that best fit them in terms of qualification, aspiration and salary expectation. There are also people changing their career paths, looking for the ones that they can leverage their previous experience and knowledge into better use. Similarly, employers are also hunting for the right candidates to fill the positions hoping to get them on board to help growing the business together with an aligned visions. In view of these bi-directional demands and needs, how to have the consolidated solutions in order to stay competitive for both parties to get the right fit for each other become an interesting topic to study.
This project outlined the focus by studying two main aspects:
Part 1 : Factors that impact salary
- which are significant decisive factors for both job seeker and employer during the consideration of an acceptance / offer
Part 2 : Factors that distinguish the job category
- which are essential for getting the right candidates with the most fit qualification and experiences , matching appropriately to the job requirements or roles and responsibilities
Data Source
Job Postings @ MyCareersFuture

Analytical Approach
1. Data Collection via Web-Scrapping
- Collect job postings that are data-related and scrap at least 1000 data to get the relevant information that is needed for subsequent analysis and prediction
2. Data Wrangling & Preparation
- Parse web-scrapped data and prepare them into dataframe for easy processing
- Perform data cleaning to clear doubtful entries and tranform into standardized types
3. Exploratory Data Analysis
- Set mean salary as the key predictive feature
- Check salary distribution and remove outliers >15k for senior positions like HOD, director in order to have normally distributed data for better prediction outcomes as general norms
4. Pre-Processing & Predictive Model Selection
- Analysing and transforming textual information using Natural Language Processing packages
- Evaluation of various classification models for best predictive model selection
5. Outlining Features Importance
- Summarizing the overall features that hold greatest significance in terms of Salary Prediction and Job Category Classification
Analytical Outcomes :
Web-Scrapping
Using BeautifulSoup and Selenium, relevant job postings linked were collected
Part 1 : to get basic job data info
driver = webdriver.Firefox(executable_path='./geckodriver')
compiled_data = []
for page in range(0,20):
url = "https://www.mycareersfuture.sg/search?search=data&page={}".format(page)
# Visit relevant page.b
driver.get(url)
# Wait few second.
sleep(3)
# Grab the page source.
html = driver.page_source
# print(html)
soup = BeautifulSoup(html, 'lxml')
compiled_data.append(list(jobPostingInfo(soup)))
driver.close()Part 2 : to get job desc + role & responsibility info
driver = webdriver.Firefox(executable_path='./geckodriver')
addOn_data = []
for i in range(0, len(compiled_data)):
page_temp = []
for j in range(20): # one page only has 20 records
temp = []
joblink = compiled_data[i][8][j]
temp.append(joblink)
joblink_url = "https://www.mycareersfuture.sg"+joblink
# Visit relevant page.
driver.get(joblink_url)
# Wait few second.
sleep(3)
# Grab the page source.
html = driver.page_source
# print(html)
soup2 = BeautifulSoup(html, 'lxml')
postDate = soup2.find('span',{'id':'last_posted_date'}).text
temp.append(postDate)
closeDate = soup2.find('span',{'id':'expiry_date'}).text
temp.append(closeDate)
job_content = soup2.find_all('div',{'id':'content'})
role_resp = job_content[0].text
temp.append(role_resp)
try:
requirements = job_content[1].text
temp.append(requirements)
except:
temp.append('-')
page_temp.append(temp)
addOn_data.append(page_temp)
driver.close()Example of the consolidated dataframe storing partial web-scrapped data
| Company | JobTitle | Location | EmploymentType | Seniority | Category | GovSupport | SalaryRange | JobLink | PostedDate | ClosingDate | RoleResponsibility | Requirements | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ASPIRE GLOBAL NETWORK PTE. LTD. | Regional Head, Ad Operations | Central | Full Time | Senior Management | Admin / Secretarial | $9,000to$13,500Monthly | /job/bde211a5a9f2b9cef2115aa6e8104a36 | 12 Apr 2018 | 12 May 2018 | A global broadcast and entertainment giant is ... | Requirements Min 6 years’ experience with Str... | |
| 1 | CYRUS TECHNOLOGY (S) PTE. LTD. | program executive | Central | Full Time | Senior Management | Admin / Secretarial | $2,000to$2,400Monthly | /job/0662cb940442cd31a25989972255c676 | 12 Apr 2018 | 12 May 2018 | Handle daily enquiries and requests from clie... | Candidate possesses Diploma in any discipline... | |
| 2 | NATIONAL UNIVERSITY HOSPITAL (SINGAPORE) PTE LTD | Case Management Officer_RCCM (Contract) | East, Central | Permanent ... | Executive | Admin / Secretarial ... | Government support available | $2,800to$5,600Monthly | /job/ef766282d386e151e6b0b863dbbf1d25 | 12 Apr 2018 | 12 May 2018 | The case management officer reviews, assessing... | Qualification: Diploma or Degree in nursing o... |
| 3 | A*STAR RESEARCH ENTITIES | Scientist / Senior Scientist (ARTC / A*STAR) | East, Central | Permanent ... | Executive | Admin / Secretarial ... | $5,900to$11,800Monthly | /job/1f70879985e4d7b0c506434c2beb82ee | 12 Apr 2018 | 12 May 2018 | The Agency for Science, Technology and Researc... | Data Scientist (SMG) Senior (at the level of... | |
| 4 | A*STAR RESEARCH ENTITIES | IMCB - Research Manager (JEC) | South | Contract ... | Executive | Healthcare / Pharmaceutical | $6,300to$12,600Monthly | /job/c9c34298cd0dc645e3d6edb902945a4c | 12 Apr 2018 | 12 May 2018 | About the Institute of Molecular and Cell Biol... | Possess MSc in Medical Biochemistry Minimum 5... | |
| 5 | TEEKAY MARINE (SINGAPORE) PTE. LTD. | Marine Personnel Officer | South | Contract ... | Executive | Healthcare / Pharmaceutical | Government support available | Salary undisclosed | /job/53701b418e11e3c29cacdc01b483df97 | 12 Apr 2018 | 12 May 2018 | Position Summary The Marine Personnel Officer ... | Diploma in Maritime/Business Administration w... |
| 6 | ST RECRUITMENT CENTRE | Admin Assistant | West | Contract ... | Senior Executive | Sciences / Laboratory / R&D | $1,800to$2,500Monthly | /job/1ac5d9d42402ff2938608515ebf9923f | 12 Apr 2018 | 12 May 2018 | To issue purchase. Do data entry. Perform sto... | Minimum GCE 'O' level. Knowledge in Excel Spr... |
Part 1 : Factors Impacting Salary Prediction
1a. Normalization of Mean Salary Distribution
After thorough data cleaning, preparation and transformation, the normalized mean salary distribution as below :
sns.distplot(df_MCF_final['mean_Salary_Monthly'], bins=30)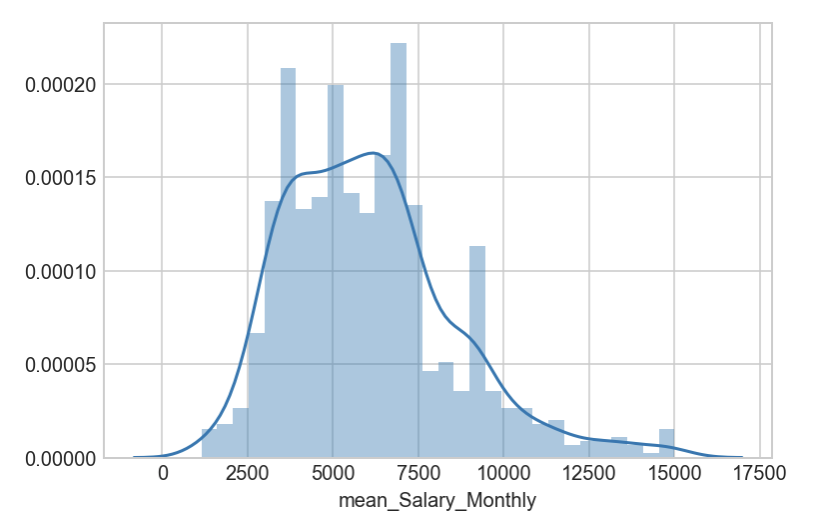
1b. Textual Transformation using NLP
- Use TF-IDF : JobTitle, Seniority, Category, RoleResponsibility, Requirements
- Use Encoder : EmploymentType, GovSupport
Example as below :
// TF-IDF on JobTitle
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
tvec = TfidfVectorizer(stop_words=stop_words, min_df=1, ngram_range=(2,2), max_features=1000)
// use ngram(2,2) because JobTitle more relevant when mentioning in pairs (business analyst)
// rather than just analyst for ngram(1,1)
tvec.fit(df_MCF_final['JobTitle'])
df_JobTitle_tvec = pd.DataFrame(tvec.transform(df_MCF_final['JobTitle']).todense(), columns=['Title_'+ v for v in tvec.get_feature_names()], index=df_MCF_final['JobTitle'].index)
// to add prefix of Title in column name, so it is clearer that these features are originally from JobTitle column
// when putting the post TF-IDF processed data into new dataframe later on combining with other post TF_IDF data
// to include index=df_MCF_final['JobTitle].index in order to have the index consistent and avoid mismatch of index
// when using pd.concat with other df later on
df_JobTitle_tvec.sum().sort_values(ascending=False)
// to use TF-IDF for subsequent modeling 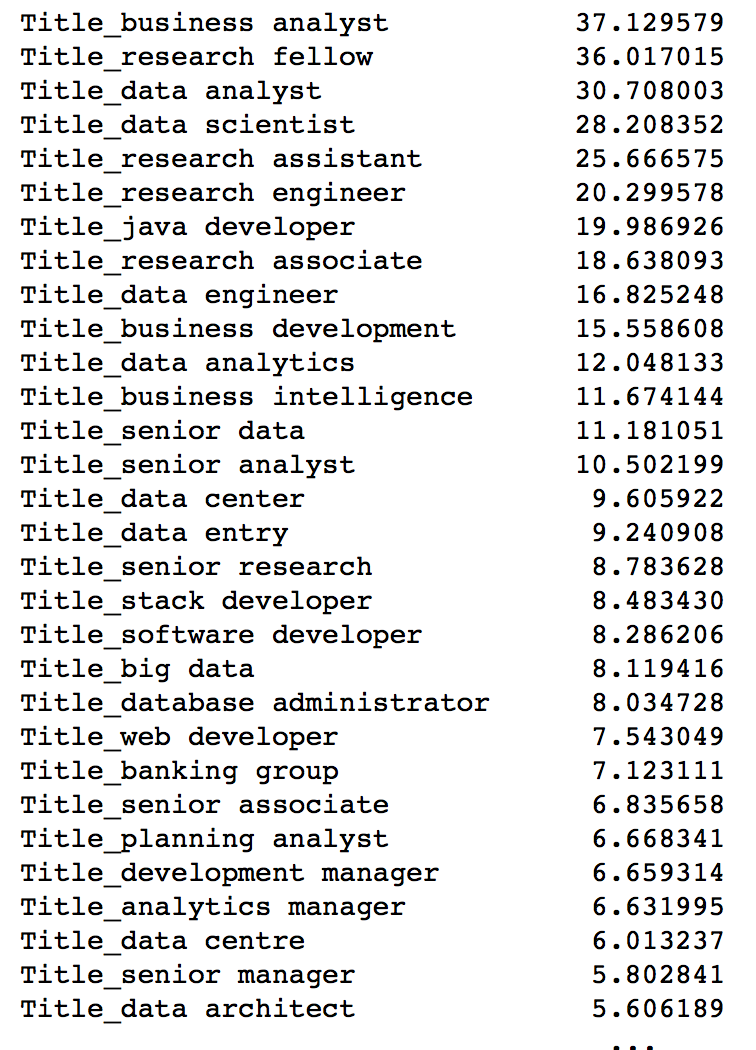
// Encoder on Employment Type:
df_EmpType = pd.get_dummies(df_MCF_final['EmploymentType'], drop_first=True, prefix= 'EmpType')
df_EmpType.head()
// first column = Contract
1c. Predictive Classification Model Selection
Categorize salary range into 4 classes below in preparation for Classification Modeling :
- <3000
- 3000 < x <= 6000
- 6000 < x <= 10000
- <10000
salary_class = []
for v in df_MCF_final['mean_Salary_Monthly']:
if v <=3000:
salary_class.append(1)
elif 3000<v<=6000:
salary_class.append(2)
elif 6000<v<=10000:
salary_class.append(3)
else:
salary_class.append(4)df_MCF_final['salary_class'].value_counts()
'''
2 468
3 377
1 74
4 59
Name: salary_class, dtype: int64Imbalance data set was observed. Therefore, need to consider sampling method for minority class before modeling
// train-test split for classifictaion modeling:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y_class, test_size=0.3, random_state=42)
// Random over sample minority class
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(ratio='minority', random_state=42)
X_res_train, y_res_train = ros.fit_sample(X_train, y_train)model_LOGR = LogisticRegressionCV(cv=5)
model_LOGR.fit(X_res_train, y_res_train)
y_predictions = model_LOGR.predict(X_test)
print('Model_LogisticRegressionCV')
print('-------------------------')
print('score = {}'.format(model_LOGR.score(X_test, y_test)))
'''
score_LogisticRegressionCV = 0.585034013605
'''Different classification models were evaluated under the similar methods and their cross validation scores were examined as below :
| Classification Model | Cross Validation Score |
|---|---|
| Logistic RegressionCV | 0.5850 |
| RidgeClassifierCV | 0.5782 |
| RandomForestClassifier | 0.5646 |
| Support Vector Classifier | 0.5816 |
Among various classification approach, Logistic RegressionCV has the highest score at 0.585. It was therefore proceeded further to check its confusion matrix and classification report
model_LOGR = LogisticRegressionCV(cv=5)
model_LOGR.fit(X_res_train, y_res_train)
y_predictions = model_LOGR.predict(X_test)
print('Model_LogisticRegressionCV')
print('-------------------------')
print('score = {}'.format(model_LOGR.score(X_test, y_test)))
print('\n')
print('Confusion Matrix :')
print('-------------------')
print(confusion_matrix(y_test, y_predictions))
print('\n')
print('Classification report :')
print('------------------------')
print(classification_report(y_test, y_predictions))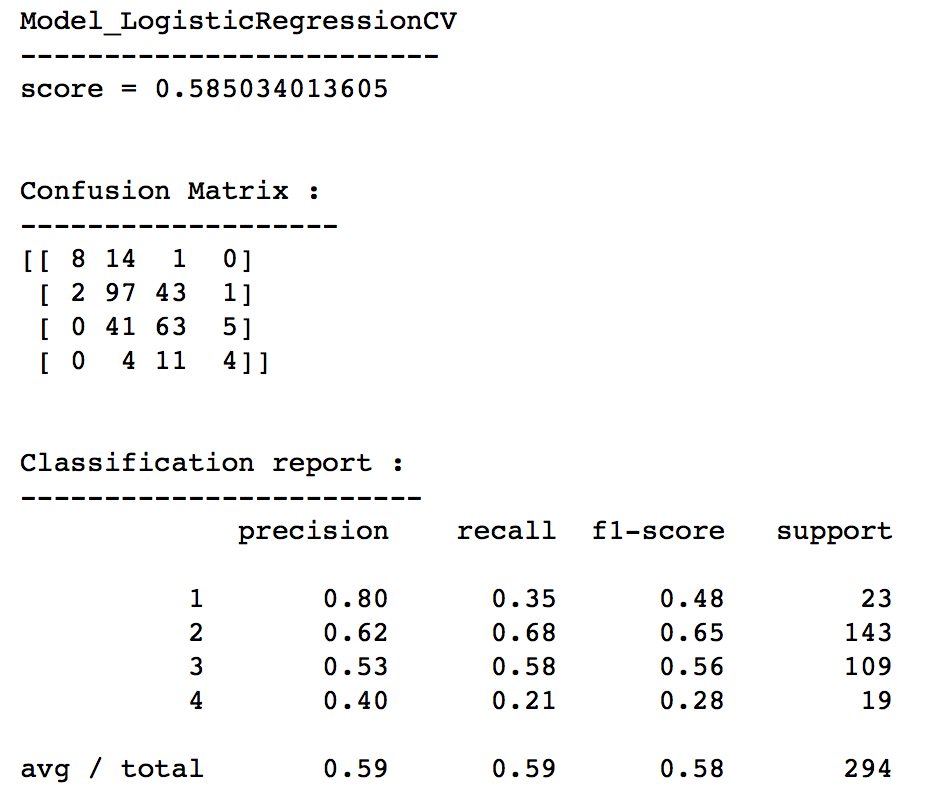
Overall accuracy with Logistic Regression CV was still poor at 0.59. Further re-examination of feature selection and study of other models shall be done to re-assess if further improvement could be achieved. However, for continuity of this exercise, extractions of feature importance for various salary classes were still demonstrated.
1d. Extraction of Feature Importance
To find out which features influencing the salary class prediction, coefficients for each salary class were extracted. The coefficients of the model could be assessed through coefs_path:
salary_coeff = model_LOGR.coefs_paths_// coefficient for each salary class determined by the index coordintes as below :
salary_coeff[1][0][0] # coefficient path for salary class 1
salary_coeff[2][0][0] # coefficient path for salary class 2
salary_coeff[3][0][0] # coefficient path for salary class 3
salary_coeff[4][0][0] # coefficient path for salary class 4Example of Features affecting Salary Class 1 :
coeff_range_class1 = salary_coeff[1][0][0]
coeff_class1_column = list(X_train.columns)
coeff_class1_dict = dict(zip(coeff_class1_column, coeff_range_class1[:-1]))
// to remove the last column coefficient(=mean salary monthly)
// form dataframe for features and their coefficients:
df_coeff_class1_raw = pd.DataFrame.from_records([coeff_class1_dict])
df_coeff_class1_LOGRCV = df_coeff_class1_raw.transpose().reset_index()
df_coeff_class1_LOGRCV.rename(columns={'index':'Feature',0:'Coefficient'},inplace=True)
// top 10 features affecting salary class 1:
df_coeff_class1_LOGRCV.sort_values('Coefficient', ascending=False).head(10)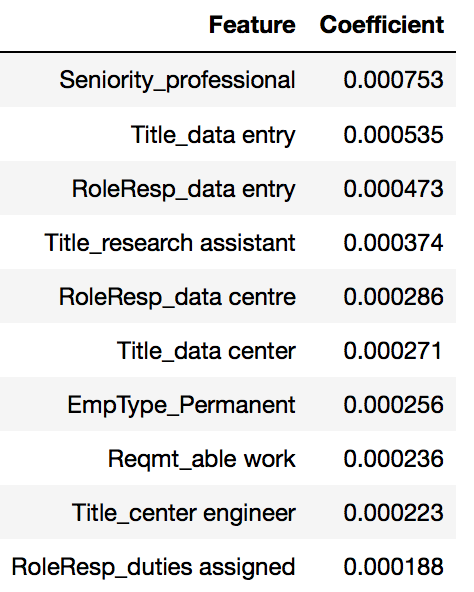
Part 2 : Factors Impacting Job Category Prediction
2a. Scope Definition to Segregate Target Job Category vs Others
Create new column to indicate if the job postings are either Data Scientist or Data Analyst
data_job_list = []
for v in df_MCF_final['JobTitle']:
if 'data scien' in v.lower():
data_job_list.append(1)
elif 'data analy' in v.lower():
data_job_list.append(1)
else:
data_job_list.append(0)
df_MCF_final['Data_JobList'] = data_job_list2b. Textual Transformation using NLP
- Use TF-IDF : RoleResponsibility, Requirements
Example as below :
// TF-IDF on RoleResponsibility
tvec = TfidfVectorizer(stop_words=stop_words, min_df=1, ngram_range=(1,3), max_features=1000)
// use ngram(2,3) because RoleResponbility more relevant when mentioning in longer word pairs
// like data analysis, years professional experience
tvec.fit(df_MCF_final['RoleResponsibility'])
df_RoleResp_tvec2 = pd.DataFrame(tvec.transform(df_MCF_final['RoleResponsibility']).todense(), columns=['RoleResp_'+ v for v in tvec.get_feature_names()], index=df_MCF_final['RoleResponsibility'].index)
df_RoleResp_tvec2.sum().sort_values(ascending=False)
2c. Predictive Classification Model Selection
// Set up X matrix for modeling:
X2_raw = pd.concat([df_Requirements_tvec2, df_RoleResp_tvec2], axis=1)
// Set up y matrix for modeling:
y2_raw = df_MCF_final['Data_JobList']// calculate baseline accuracy
baseline = y2_raw.value_counts().max()/float(len(y2_raw))
print('Baseline : {:0.4}'.format(baseline))
'''
Baseline : 0.8824
'''X2_train, X2_test, y2_train, y2_test = train_test_split(X2_raw, y2_raw, test_size=0.3, random_state=42)
// Random over sample minority class
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(ratio='minority', random_state=42)
X2_res_train, y2_res_train = ros.fit_sample(X2_train, y2_train)
// 1st model trial : LogisticRegressionCV
model_LOGRCV2 = LogisticRegressionCV(cv=5)
model_LOGRCV2.fit(X2_res_train, y2_res_train)
y2_predictions = model_LOGRCV2.predict(X2_test)
// 2nd model trial : RidgeClassifierCV
model_RClass = RidgeClassifierCV()
model_RClass.fit(X2_res_train, y2_res_train)
y_pred = model_RClass.predict(X2_test)
// 3rd model trial : KNN
model_knn = KNeighborsClassifier()
model_knn_params = {'n_neighbors': range(1, 20, 2),
'weights': ['uniform', 'distance']}
knn_Gsearch = GridSearchCV(model_knn, model_knn_params, n_jobs=3, cv=5, verbose=1)
knn_Gsearch.fit(ss.fit_transform(X2_raw), y2_raw)
// 4th model trial : decision tree classifier
model_dtreec = DecisionTreeClassifier(random_state=42)
model_dtreec.fit(ss.fit_transform(X2_raw), y2_raw)
model_dtreec.predict(X2_test)// Summary of all model trials:
print('1. Score_LogisticRegressionCV \t= {}'.format(model_LOGRCV2.score(X2_test, y2_test)))
print('2. Score_RidgeClassifierCV \t= {}'.format(model_RClass.score(X2_test, y2_test)))
print('3. Score_KNN \t\t\t= {}'.format(knn_best.score(X2_test, y2_test)))
print('4. Score_DecisionTreeClassifier = {}'.format(model_dtreec.score(X2_test, y2_test)))
Since Logistic Regression CV yielded the highest score, it was used to examine what components in the job posting that leaded to the differentiation of the job category (Data Scientist/Data Analyst) vs others
2d. Extraction of Feature Importance
Examination of which features had the higher influence on job category prediction
model_LOGRCV2.coefs_paths_[1][0][0]
coeff_column = list(X2_train.columns)
coeffients_LOGRCV2 = [v for v in model_LOGRCV2.coefs_paths_[1][0][0]]
coeff_dict = dict(zip(coeff_column, coeffients_LOGRCV2[:-1]))
// to remove the last column coefficient(=mean salary monthly)
// form dataframe for features and their coefficients:
df_coeff_raw = pd.DataFrame.from_records([coeff_dict])
df_coeff_LOGRCV = df_coeff_raw.transpose().reset_index()
df_coeff_LOGRCV.rename(columns={'index':'Feature',0:'Coefficient'},inplace=True)
df_coeff_LOGRCV.sort_values('Coefficient', ascending=False).head(20)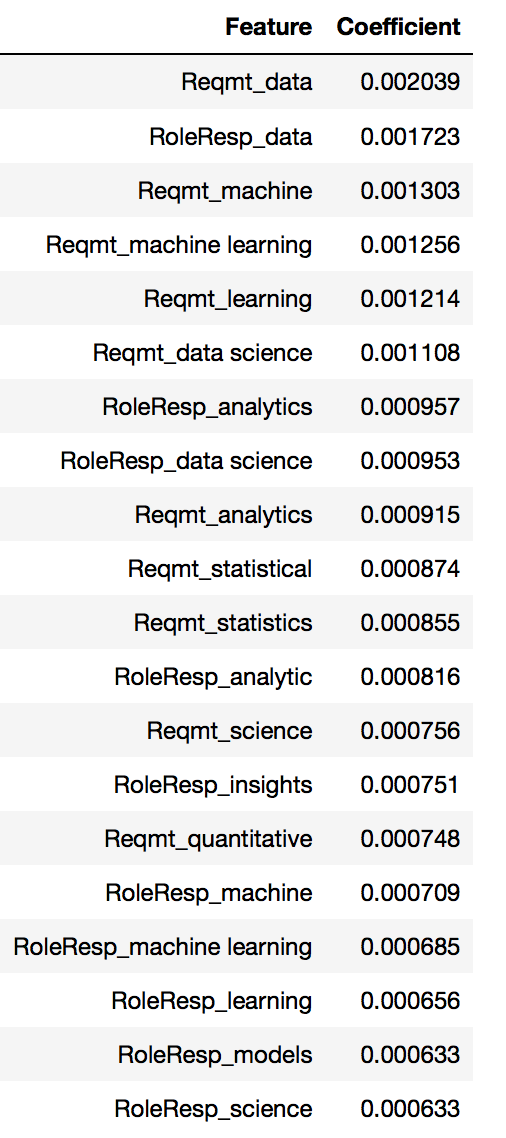
Summary
Part 1: Salary Trend Prediction
Classification Approach :
| Model | Cross Validation Score |
|---|---|
| Logistic Regression CV | 0.5850 |
| RidgeClassifierCV | 0.5782 |
| RandomForestClassifier | 0.5646 |
| SupportVectorClassifier | 0.5816 |
Classification approaches still yield poor results indicating further re-examination of feature selection and deeper study of other models to assess next level of improvement could be tried. For continuity and completion of the exercise, Logistic Regression CV was chosen as final model predicting the salary since it yielded the highest score.
Accuracy for salary range predicted using chosen model ( Log Regression CV ) as below :
| Salary Class | Accuracy |
|---|---|
| <= $3000 - class 1 | 0.80 |
| $3000 - $6000 - class 2 | 0.62 |
| $6000 - $10000 - class 3 | 0.53 |
| >$10000 - class 4 | 0.40 |
Summary of the Top 10 features for various Salary Classes as below :

Part 2: Job Category Prediction
Summary of All Model Trials:
| Model | Cross Validation Score |
|---|---|
| LogisticRegressionCV | 0.9388 |
| RidgeClassifierCV | 0.9354 |
| KNN | 0.9014 |
| DecisionTreeClassifier | 0.9014 |
Differentiation Key Words
Key words obtained from the model ( Logistic Regression CV ) which predicting the differentiation in job posting of DataScientist/DataAnalyst from other jobs are :
- Data
- Machine learning
- Data science
- Analytics
- Statistic
- Insights
- Quantitative
- Models
These key words are well related to Data scientist/analyst job. Therefore model chosen is relative robust with accuracy at 0.94